프로그래머스 코딩테스트 DFS/BFS 여행경로 JAVA DEV / ALGORITHM
2021-10-15 posted by sang12
어떤문제
일까? (출처:https://programmers.co.kr/learn/courses/30/lessons/43164)해당 문제는 항공권 정보가 담긴 2차원 배열 TICKETS가 주어지고, 항공권을 사용해서 공항을 경유하는 경로를 찾는 문제이다. 이때 모든 항공권을 다 사용해야 하고, 알파벳 순서가 앞서는 경로를 찾아야 한다.
어떻게
풀었을까?아래와 같이 티켓 {{"ICN", "SFO"}, {"ICN", "ATL"}, {"SFO", "ATL"}, {"ATL", "ICN"}, {"ATL","SFO"}}이 주어 졌을 때, ICN 을 시작으로 전체 항공권을 사용 할 수 있는 경우를 LEVEL6까지 탐색하면 항공권을 전체 다 사용 할 수 있는 경우를 구할 수 있다. 해당 문제를 보고 이 그림을 떠올리는게 문제를 푸는 핵심이였던거 같다.
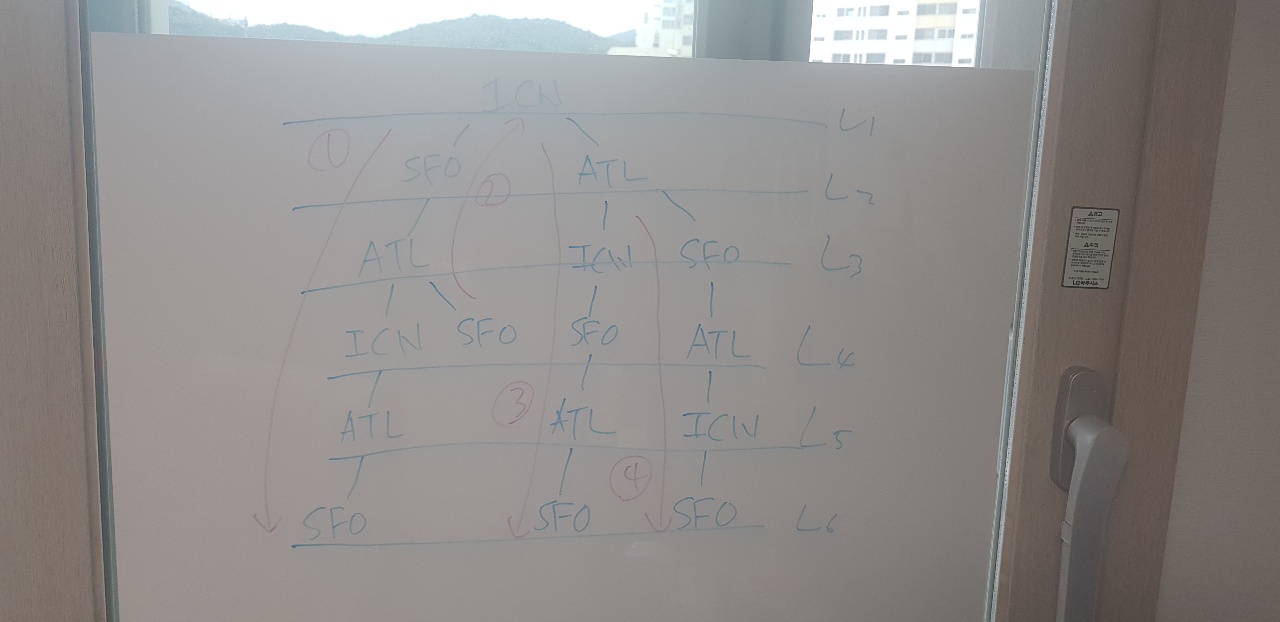
사진을 보면 모든 항공권을 사용 할 수 있는 경우는 3가지 경우가 있다는 것을 알 수 있다.
1. ICN->SFO->ATL->ICN->ATL->SFO
2. ICN->ATL->ICN->SFO->ATL->SFO
3. ICN->ATL->SFO->ATL->ICN->SFO
이때, 경로가 같을 경우 알파벳 순으로 지정한다고 했으니 답은 2번이 된다. 트리를 생각하는거에 + 정렬순서를 둠으로 문제가 더욱 까다러웠던거 같다. 정렬을 생각하며 다른길로 샐수도... 저와같이..ㅎ
코드(https://github.com/ChoiSangIl/algorithm/tree/master/BFS%2CDFS/programmers_C30_L43164_%EC%97%AC%ED%96%89%EA%B2%BD%EB%A1%9C)
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
class A211015 {
static ArrayList<String> result = new ArrayList<String>();
public static void main(String[] args) {
String[][] tickets = {{"ICN", "SFO"}, {"ICN", "ATL"}, {"SFO", "ATL"}, {"ATL", "ICN"}, {"ATL","SFO"}};
A211015 s = new A211015();
System.out.println(Arrays.toString(s.solution(tickets)));
}
public String[] solution(String[][] tickets) {
//방문경로를 저장하기위한 배열
Boolean[] visited = new Boolean[tickets.length];
Arrays.fill(visited, Boolean.FALSE);
//깊이탐색 시작
dfs(visited, "ICN", "", tickets, 0);
//알파벳순서로 가장 빠른 경로를 가져오기 위한 정렬
Collections.sort(result);
String[] answer = result.get(0).split(",");
return answer;
}
static void dfs(Boolean[] visited, String station, String path, String[][] tickets, int index) {
if("".equals(path)) {
path = station;
}else {
path = path + ","+ station;
}
if(index == tickets.length) {
result.add(path);
}
for(int i=0; i<tickets.length; i++) {
//사용하지 않은 티켓이고 가는 경로가 있을 경우
if(!visited[i] && tickets[i][0].equals(station)) {
visited[i] = true;
dfs(visited, tickets[i][1], path, tickets, index+1);
visited[i] = false;
}
}
}
}
프로그래머스 코팅테스트 DFS/BFS 단어 변환 JAVA DEV / ALGORITHM
2021-09-08 posted by sang12
어떤문제
일까? (출처:https://programmers.co.kr/learn/courses/30/lessons/43163)
해당 문제는 begin과 target 단어가 주어지고, 주어진 단어 배열을 이용하여 한개의 알파뱃씩을 변경하여 begin에서 target으로 변환 할 수 있는 최소 단계를 찾는 문제이다.
어떻게
풀었을까?begin으로 부터 시작되는 트리를 만들어, 탐색할수 있는 노드들( 1개의 단어로 변환 가능한 )을 깊이 우선 탐색을 하여, target에 도달 했을 때의 depth를 반환 하면 답을 구할 수 있지 않을까 생각했다.

target 단어인 hit를 시작으로 변환 가능한 노드들을 따라서 깊이 탐색을 한다. 이때, stack이란 배열을 이용하여 탐색을 한 노드들을 제외하고 시작단어 + 단어의 개수인 최대 depth까지 탐색 하도록 한다. 이때, 탐색 노드와 target단어가 같으면 해당 depth를 리턴한다. 그러면 최종적으로 모든 노드들을 탐색하게 되고, 이때 리턴되는 최소값이 최소 변환 횟수가 된다.
코드
(https://github.com/ChoiSangIl/algorithm/tree/master/BFS%2CDFS/programmers_C30_L43163_words)
import java.util.ArrayList;
import java.util.Arrays;
public class A20210907 {
public static void main(String[] args) {
String begin = "hit";
String target = "cog";
String[] words = {"hot", "dot", "dog", "lot", "log", "cog"};
ArrayList<String> stack = new ArrayList<String>();
int result = dfs(begin, target, words, stack, 0);
System.out.println(result);
}
public static int dfs (String begin, String target, String[] words, ArrayList<String> stack, int depth) {
stack.add(begin);
System.out.println(stack);
if(begin.equals(target)) {
stack.remove(begin);
return depth;
}
int result = 0;
for(int i=0; i<words.length; i++) {
int wordCheck = 0;
//변환 가능한지 체크
for(int j=0; j<words[i].length(); j++) {
if(begin.charAt(j) == words[i].charAt(j)) {
wordCheck = wordCheck + 1;
}
}
//단어 변환이 가능하면, 해당 노드를 깊이 탐색한다.
if(wordCheck == words[i].length()-1 && !stack.contains(words[i])) {
int particleResult = dfs(words[i], target, words, stack, depth+1);
if(result == 0) {
result = particleResult;
}else {
if(particleResult != 0) {
result = Math.min(result, particleResult);
}
}
}
}
stack.remove(begin);
return result;
}
}
어떤게
어려웠을까?
단어가 변환 가능한지 체크 하는 부분을 처음엔 replace 하는 방법으로 구현을 하였는데, aaa -> aab와 같은 경우를 생각 하지 못했다. 그래서 words의 크기 -1개의 단어가 똑같은 단어가 있으면 통과되게 변경 하였다. (해당 체크로직을 사소하다고 생각하고 쉽게 넘어갔다, 다양한 케이스를 생각 못함)
개선할점
은 없을까?해당 접근방법으로 문제를 풀때, DFS보다 BFS방식으로 탐색을 하면 더욱 좋은 퍼포먼스가 나올 수 있겠다라는 생각이 들었다. DFS방식으로 풀면 최소값을 찾아야 하기 때문에 전체 노드들을 순회해야 하지만, BFS방식으로 풀면 target값을 처음 찾는 순간이 최소값이기 때문이다. 물론 최악의 경우는 비슷하겠지만... 다음엔 BFS방식으로 풀어봐야겠다.
프로그래머스 코딩테스트 연습(BFS/DFS) 네트워크 JAVA DEV / ALGORITHM
2021-08-30 posted by sang12
왜? (문제 출처 : https://programmers.co.kr/learn/courses/30/lessons/43162)
못 풀었을까?
1. DFS를 사용할 방법은 생각 했지만, 활용을 하지 못했다.
-> 모든 노드에서 DFS 탐색을 하지 않아도 된다. 연결이 되어 있다면 연결된 노드는 패스하고 연결되지 않은 노드부터 탐색해야 하는데 해당 부분을 생각하지 못했다.
어떻게 풀면 될까?
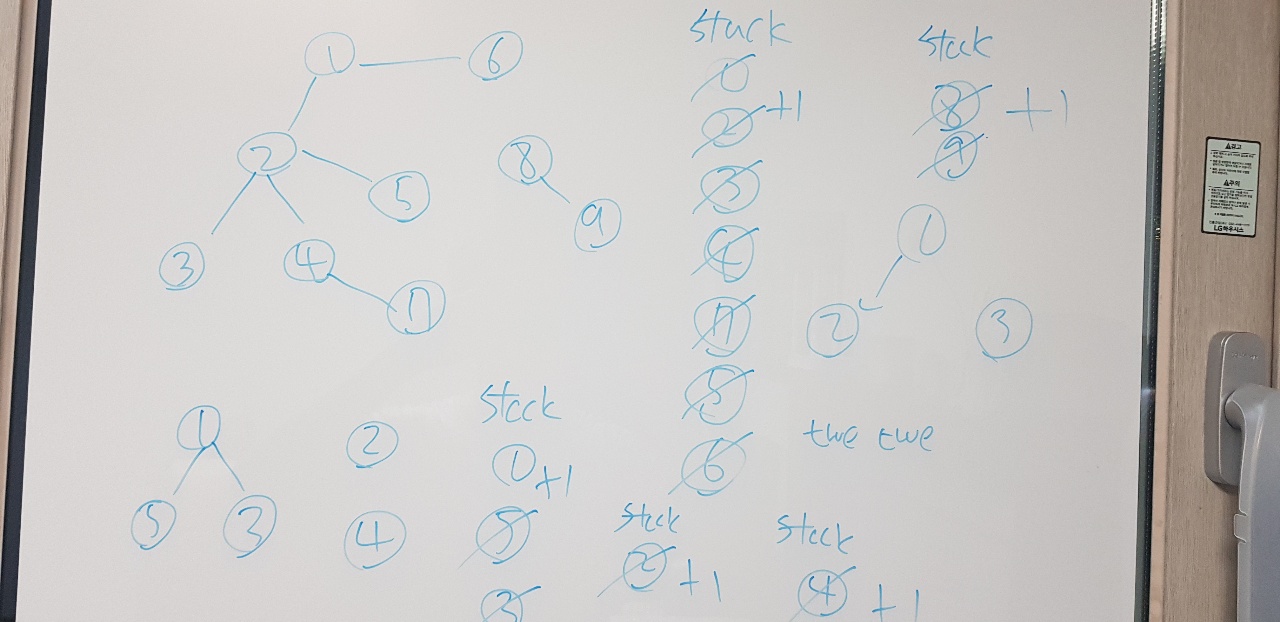
1. STACK ( 1->2->3 )
2. STACK ( 1->2 )
3. STACK ( 1->2->4 )
4. STACK ( 1->2->4->7 )
5. STACK ( 1->2->4 )
6. STACK ( 1->2 )
7. STACK ( 1->2-> 5)
8. STACK ( 1->2 )
9. STACK ( 1-> 6 )
10. STACK ( 1 )
11. STACK ()
위의 노드를 다 순회하고 나면, 순회한 노드들은 다 연결 되어 있다는 것을 알 수 있다.
그러므로 해당 노드들은 다시 탐색할 필요가 없다. 이를 PATH[] 배열을 이용하여 연결되었음을 TRUE값으로 넣어주고, 해당 순회가 끝나면 PATH 배열에 연결되어 있지 않은 노드들부터 다시 순회하면 해당 문제를 풀 수 있다.
-JAVA 소스 : https://github.com/ChoiSangIl/algorithm/tree/master/BFS%2CDFS/progrmmers_C30_L43162_networks
DFS로 생각 할때는 STACK으로 생각하는게 쉬워서 STACK을 사용했지만, 구현은 재귀 함수로 구현했다. 처음엔 재귀함수로 짜는것도 이해가 안되었는데, 프로그래머스 연습문제 타겟넘버가 많은 도움이 됐다(https://programmers.co.kr/learn/courses/30/lessons/43165)
class Solution {
public int solution(int n, int[][] computers) {
int answer = 0;
boolean[] path = new boolean[n];
for(int i=0; i<n; i++) {
path[i] = false;
}
for(int j=0; j<n; j++) {
if(!path[j]) {
answer ++;
dfs(j, computers, path);
}
}
return answer;
}
public static void dfs(int index, int[][] computers, boolean[] path) {
path[index] = true;
for(int i=0; i<computers.length; i++) {
if(path[i] == false && computers[index][i] == 1) {
dfs(i, computers, path);
}
}
}
}